How to read tabular data from a text file in Fortran
In this post, we will read a formatted text file with tabular data (Earth model) file using Fortran.
Tabular data
For reading any formatted data file, the first step is to get an idea of the data format. The example data file for this post has three lines of header (it is also some sort of data but we ignore it for this post), and the rest of the lines are space-separated columns. We have seen many posts where we have read such files using Pandas library in Python. But for many geophysical applications, we need to read such files using fortran.
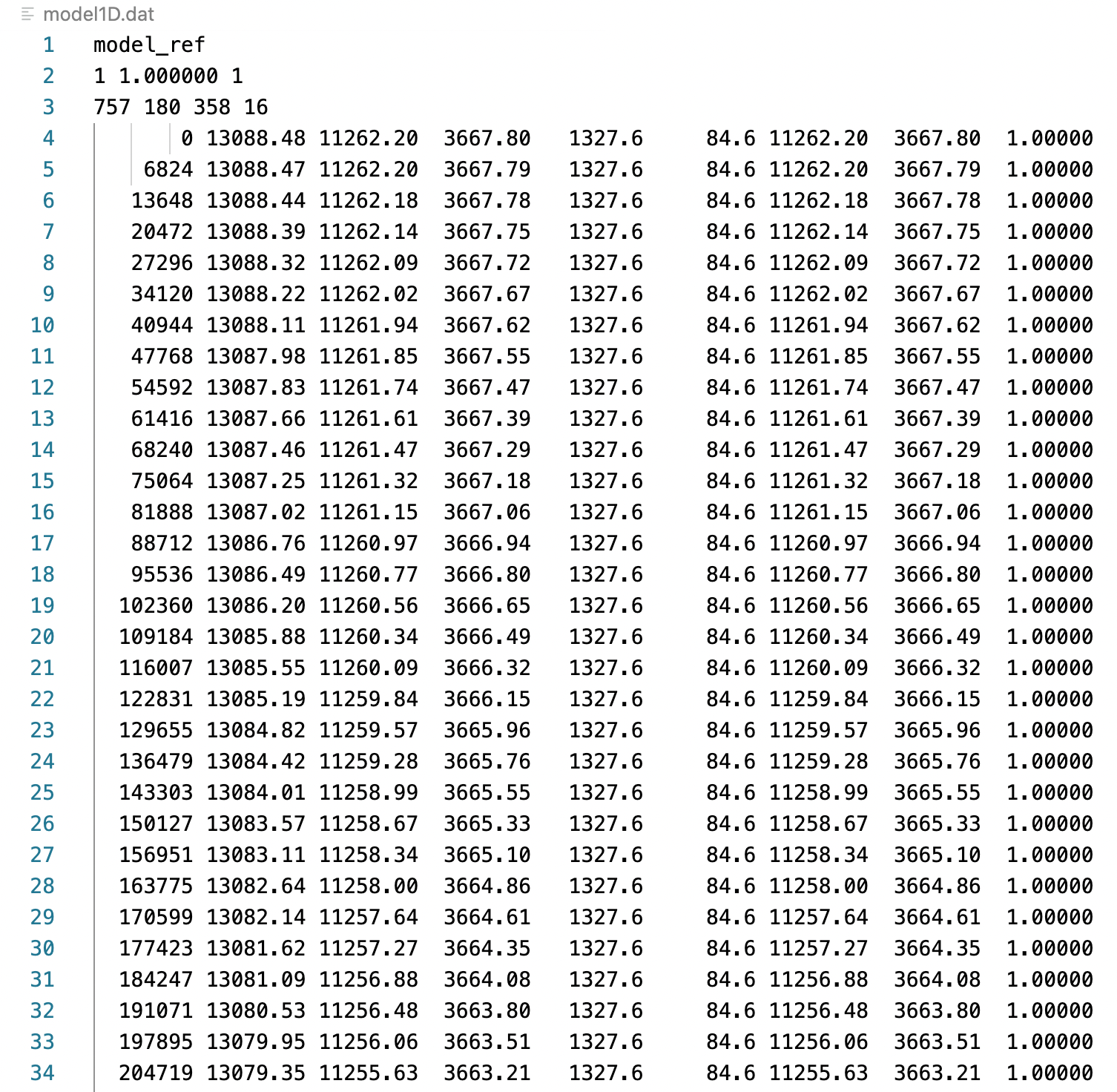
Our task is to read and store each of the columns of the file in arrays for further manipulation. Here, we are reading a file containing the 1D earth model. The columns of this file are from left to right - radius,density,Vpv,Vsv,Q-kappa (bulk),Q-mu (shear),Vph,Vsh,and eta.
Begin the program and declare variables
First step for writing a Fortran script is to initiate a program and declare the name and type of the variables to be used in the code.
!Read the model1D.dat file to determine moho radius
program read_model
implicit none
!! Declare vars
integer :: FID = 10 !file identifiers
character*256 :: CTMP !dummy var
real (kind=8), allocatable :: radius(:),density(:),vpv(:),vsv(:),qkappa(:),qmu(:),vph(:),vsh(:),eta(:) !columns of the model file
real (kind=8), allocatable :: derivdensity(:) !new array to store the derivative of density
integer, allocatable :: discontLayer(:) !another array
integer :: i = 0, IERR = 0, NUM_LINES = 0, mohoDiscontNum = 2 !some dummy parameters to be used
integer :: j, totalDiscont !dummy var without initial values
end program read_model
Fortran90 allows for “allocatable” arrays. This means that the maximum size of the arrays can be left to be allocated later in the code.
Read the file and get the number of layers
Now, we can open and read the file. We first need to estimate the number of layers in the file, so that we can better allocate the size of the arrays that we created to store the column values.
program read_model
implicit none
!! Declare vars
integer :: FID = 10
character*256 :: CTMP
real (kind=8), allocatable :: radius(:),density(:),vpv(:),vsv(:),qkappa(:),qmu(:),vph(:),vsh(:),eta(:)
real (kind=8), allocatable :: derivdensity(:)
integer, allocatable :: discontLayer(:)
integer :: i = 0, IERR = 0, NUM_LINES = 0, mohoDiscontNum = 2
integer :: j, totalDiscont
open(FID, file='model1D.dat', status="old")
! Get number of lines
read( FID, * ) !! skip the header
read( FID, * )
read( FID, * )
do while (IERR == 0)
NUM_LINES = NUM_LINES + 1
read(FID,*,iostat=IERR) CTMP
end do
NUM_LINES = NUM_LINES - 1
write(*,'(A,I0)') "Total number of layers: ", NUM_LINES
! Allocate array of strings
allocate(radius(NUM_LINES), density(NUM_LINES), vpv(NUM_LINES), vsv(NUM_LINES), qkappa(NUM_LINES))
allocate(qmu(NUM_LINES), vph(NUM_LINES),vsh(NUM_LINES),eta(NUM_LINES))
allocate(derivdensity(NUM_LINES))
close(FID)
deallocate(radius,density,vpv,vsv,qkappa,qmu,vph,vsh,eta,derivdensity)
end program read_model
In the above code, we have opened an existing file, ‘model1D.dat’, and looped through it to estimate the number of layers. Also, note that we have skipped the first three lines of the file as they only contain some header information.
Then we used the estimated number of layers to assign the size of the column arrays. Finally, it is a good practice to deallocate the arrays to free up the memory.
Read the columns into defined arrays and perform data manipulation
Now, we need to loop through each layers (or rows), and get the column values into the defined data arrays.
!Read the model1D.dat file to determine moho radius
program read_model
implicit none
!! Declare vars
integer :: FID = 10
character*256 :: CTMP
real (kind=8), allocatable :: radius(:),density(:),vpv(:),vsv(:),qkappa(:),qmu(:),vph(:),vsh(:),eta(:)
real (kind=8), allocatable :: derivdensity(:)
integer, allocatable :: discontLayer(:)
integer :: i = 0, IERR = 0, NUM_LINES = 0, mohoDiscontNum = 2
integer :: j, totalDiscont
open(FID, file='model1D.dat', status="old")
! Get number of lines
read( FID, * ) !! skip the header
read( FID, * )
read( FID, * )
do while (IERR == 0)
NUM_LINES = NUM_LINES + 1
read(FID,*,iostat=IERR) CTMP
end do
NUM_LINES = NUM_LINES - 1
write(*,'(A,I0)') "Total number of layers: ", NUM_LINES
! Allocate array of strings
allocate(radius(NUM_LINES), density(NUM_LINES), vpv(NUM_LINES), vsv(NUM_LINES), qkappa(NUM_LINES))
allocate(qmu(NUM_LINES), vph(NUM_LINES),vsh(NUM_LINES),eta(NUM_LINES))
allocate(derivdensity(NUM_LINES))
! Read the file content
rewind(FID)
read( FID, * ) !! skip the header
read( FID, * )
read( FID, * )
do i = 1, NUM_LINES
read(FID,*) radius(i), density(i), vpv(i), vsv(i), qkappa(i),qmu(i), vph(i),vsh(i),eta(i) !Read the data
! print*, i, radius(i), density(i), vpv(i), vsv(i), qkappa(i),qmu(i), vph(i),vsh(i),eta(i) !! Print out the results
end do
! find the discontinuities
totalDiscont = 0
do i = 1, NUM_LINES-1
if (radius(i+1)-radius(i) == 0 ) then
derivdensity(i) = -99999.
! write(*,11) i, derivdensity(i), radius(i), density(i), vpv(i), vsv(i), qkappa(i),qmu(i), vph(i),vsh(i),eta(i)
! 11 format(I5,12F12.2)
totalDiscont = totalDiscont + 1
else
derivdensity(i) = (density(i+1)-density(i))/(radius(i+1)-radius(i))
end if
end do
write(*,12) "Total discontinuities: ", totalDiscont
12 format(A,I5)
! get the layer numbers
allocate(discontLayer(totalDiscont))
j = 1
do i = 1, NUM_LINES-1
if (radius(i+1)-radius(i) == 0 ) then
discontLayer(j) = i
j = j + 1
end if
end do
! print the moho radius, 2nd last discontinuity
mohoDiscontNum = mohoDiscontNum-1
write(*,12) 'Moho layer number is: ',discontLayer(totalDiscont-mohoDiscontNum)
close(FID)
deallocate(radius,density,vpv,vsv,qkappa,qmu,vph,vsh,eta,derivdensity)
deallocate(discontLayer)
end program read_model
The above code loop through the rows of the file, and store the values into arrays. Next, we use the arrays to estimate the discontinuities in the file (where the layer depths are not changing). For such layers, we defined the derivate of the density to be some unexpected value. This can be helpful in differentiting it from other derivatives. In this code, I used the value of -99999.0.
Next, we loop through the layers to get the layer numbers for the discontinuities. Finally, we extract the layer number for the second discontinuity.
Conclusion
In this post, I shared a quick script to read and manipulate an example dataset. One can use this script as an example to read and extract any tabular data from text files.
PS: To download the script to determine the Moho discontinuity in the 1D Earth model, visit my github repo.
Disclaimer of liability
The information provided by the Earth Inversion is made available for educational purposes only.
Whilst we endeavor to keep the information up-to-date and correct. Earth Inversion makes no representations or warranties of any kind, express or implied about the completeness, accuracy, reliability, suitability or availability with respect to the website or the information, products, services or related graphics content on the website for any purpose.
UNDER NO CIRCUMSTANCE SHALL WE HAVE ANY LIABILITY TO YOU FOR ANY LOSS OR DAMAGE OF ANY KIND INCURRED AS A RESULT OF THE USE OF THE SITE OR RELIANCE ON ANY INFORMATION PROVIDED ON THE SITE. ANY RELIANCE YOU PLACED ON SUCH MATERIAL IS THEREFORE STRICTLY AT YOUR OWN RISK.